
Le problème
Peut-être comme moi vous êtes vous souvent posé la question de savoir comment dimensionner un pool JDBC. Y a-t-il des abaques? Comment savoir si les ressources allouées au pool sont suffisantes? J’ai assez souvent entendu des règles dogmatiques du genre une connexion pour 5 utilisateurs ou encore 42 connexions, généralement c’est bien, et puis au final, le pool est réglé en attente infinie donc l’application ne génère aucune erreur sur l’obtention de connexion.
Ces règles sont évidemment toutes fausses et je vais le démontrer rapidement.
Soit le cas d’une application web Java sous Tomcat. Chaque connecteur HTTP du conteneur exploite un pool de 200 threads max (valeur par défaut, c’est configurable). Chaque requête HTTP va donc occuper un thread le temps du traitement (en mode synchrone) et ce quel que soit le nombre d’utilisateurs. Pour la suite du raisonnement, considérons que les ressources statiques (js, images, css) figurent déjà dans les caches des navigateurs clients, impliquant que chaque requête HTTP ne génère que du contenu dynamique. On peut très bien avoir un utilisateur productif (ou névrosé?) générant plus d’activité que plusieurs utilisateurs normaux. Donc déjà un ratio par utilisateur, cela ne fonctionne pas.
Puisqu’on dispose de 200 threads dans le pool du connecteur, cela signifie que notre conteneur pourra traiter au max 200
requêtes HTTP simultanément. Du coup, pourquoi ne pas aligner le nombre de connexions JDBC sur le pool HTTP? Ça paraît
un peu surdimensionné non? En fait non. Ouch. Cela peut même être sous dimensionné.
WAT? Je m’explique : si l’application utilise des transactions REQUIRES_NEW, alors un thread
monopolise plus d’une connexion JDBC pour servir une seule requête HTTP qui implique une transaction REQUIRED et une
REQUIRES_NEW imbriquée.
Bon après une requête HTTP ne sollicite pas la base du début jusqu’à la fin, notamment elle n’en a pas besoin pour
générer le HTML. Enfait, là encore cela dépend… Si l’application exploite la base au travers de JPA et avec une
configuration du genre OpenEntityManagerInView (ou encore avec un contexte de persistance étendu) permettant de ne
pas se préoccuper des remontées de relation tardives ( lazy loading ) au sein de la vue, alors la connexion JDBC
est restituée seulement à la fin de la génération de la vue.
Alors comment on fait?
Il n’y a évidemment pas de règle dogmatique puisque vous venez de comprendre que ce paramètre était hautement dépendant de l’application comme de l’activité (évidemment). Que nous reste-t-il? L’expérimentation. Il faut observer le comportement de l’application face à une charge représentative de l’activité (ou d’une partie de l’activité à partir de laquelle une projection pourra être déduite).
Ensuite pour savoir comment positionner le réglage par rapport à votre système, le cas simple est d’avoir un outil de monitoring qui historise le taux de saturation de votre pool et de trouver le réglage adéquat par dychotomie.
Oui mais si on en a pas (ou pas encore)? Comment peut-on savoir que le dimensionnement est pertinent? Déjà on va se fixer un objectif d’attente maximale pour obtenir une connexion, disons 10 ms. Je ne trouve pas que cela soit agressif car si on espère que les requêtes soient honorées en un temps minimal, l’application ne peut évidemment pas se permettre d’attendre trop longtemps sans rien faire.
J’ai dans ma boîte à outils une application Spring + JPA + HSQLDB qui permet un comportement à “géométrie variable”: elle comprend une douzaine de problèmes de performance débrayables durant l’exécution. Elle vient de chez Xebia et, avec @framiere, nous l’avons enrichie de quelques bugs. Pour ce billet, elle est configurée pour exploiter de façon intensive la base de donnée avec des requêtes légères mais nombreuses et des requêtes plus lourdes. En gros une application JPA codée avec les pieds les yeux bandés. La routine quoi.
Je vous propose deux méthodes pour trouver le temps d’attente.
Par Profiling
Vous devez disposer d’un profiler capable de faire du suivi sur les moniteurs. Donc pas VisualVM. J’utilise JProfiler. J’applique avec JMeter une charge simulée de 10 utilisateurs, le scenario comprenant un think time assez bas de 100ms, on a quasiment une correspondance 1:1 entre les utilisateurs et les requêtes HTTP simultanées dans ce contexte.
En examinant la timeline JDBC, je constate la présence d’une activité soutenue:
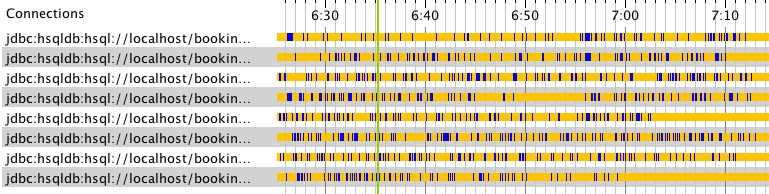
Lorsque le tir est arrivé au plateau, je déclenche le suivi des moniteurs dans JProfiler ( Monitors and locks / Monitor History ) durant quelques secondes. Ensuite je demande à JProfiler de générer une vue agrégée par classe de moniteurs ( Calculate statistics ):
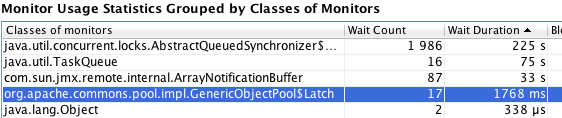
Ce ne sont pas les locks qui vont m’intéresser ici mais les waits. La classe est mise en évidence car elle est utilisée par commons-dbcp, le pool qui équipe l’appli. Je sais, il est périmé mais on le retrouve souvent dans les projets. Donc durant la période enregistrée, il y a eu 17 événements qui ont duré au total 1768ms, les voici :
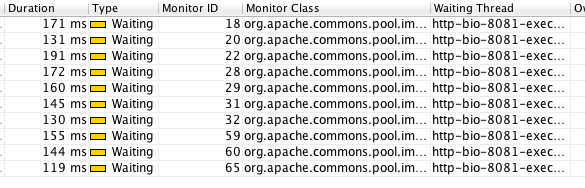
On est donc loin des 10ms…
Je reconfigure le pool afin qu’il soit capable de provisionner jusqu’à 20 connexions et je relance le tir. Je n’ai plus d’attente sur le latch de commons-pool et ce sont maintenant 10 connexions qui sont exploitées:
Donc mon objectif est atteint avec une connexion par requête HTTP sur cette application.
Avec les timeouts
Je n’ai donc pas de profiler (c’est ballot car il ne coûte pas si cher que ça et il rend énormément de services). Cette fois la méthode est moins sexy. L’idée est de paramétrer le temps d’attente maximal ( maxWait ) pour obtenir une connexion dans la configuration du pool et ensuite observer les exceptions générées sous charge. Je tire avec un maxWait à 10ms et rapidement je trouve dans les logs :
2014/05/15 16:39:28 [http-bio-8081-exec-63] ERROR o.h.util.JDBCExceptionReporter -
Cannot get a connection, pool error Timeout waiting for idle object
Je repositionne le nombre de connexions maximal à 10 et je relance le tir pour confirmer les résultats précédents par l’absence de nouvelles erreurs (en tous cas chez moi ça marche :o) ).
Le mot de la fin
Historiquement la mission d’un pool JDBC était de partager les connexions et d’éviter de payer le coût de connexion à chaque requête. Nous sommes en 2014 et il me semble que seul le dernier objectif soit toujours d’actualité, il paraît dommage de troquer l’attente de vos utilisateurs pour quelques connexions économisées.
Si l’application rationalise les échanges avec le tiers de persistance (bug liés à JDBC désactivés), une seule connexion suffit pour être en conformité avec les 10ms fixées pour les 10 utilisateurs concurrents. Mais n’allez pas retenir qu’une connexion pour 10 utilisateurs est suffisante si l’application est correctement réalisée ;-) …